Home /
Expert Answers /
Computer Science /
python-question-flag-questio-idf-measures-how-important-a-term-is-throughout-the-corpus-while-compu-pa796
(Solved): python question Flag questio IDF measures how important a term is throughout the corpus. While compu ...
python question

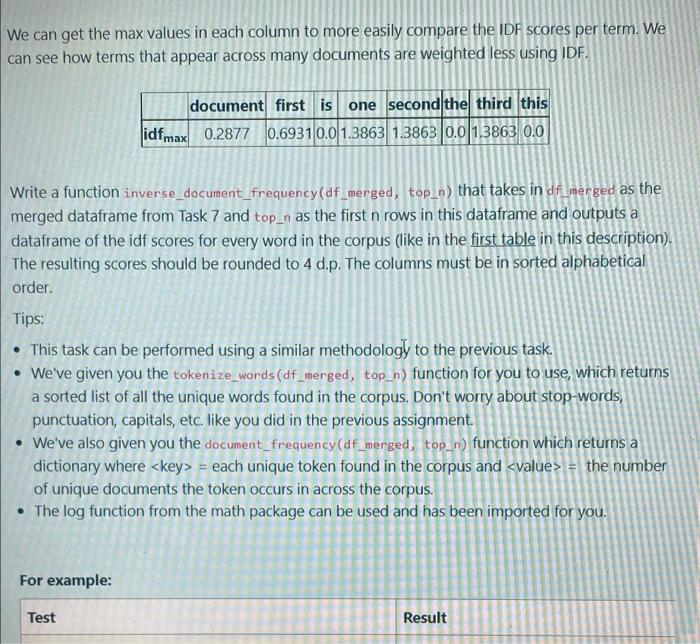
Flag questio IDF measures how important a term is throughout the corpus. While computing TF, all terms are considered equally important. However it is known that certain terms, such as "is", "of", and "that", may appear a lot of times but have little importance. TF will tend to incorrectly emphasize documents which happen to use common words more frequently, without giving enough weight to the more meaningful terms. In computing IDF, we can weigh down the frequent terms while scaling up the rare ones. The formula for IDF is: idf(t, D) = log(total number of documents/ (number of documents with term t in it)). where t = a particular term (or word) in a document and D is the corpus. Consider the examples: ? do: "this is the first document" d?: "this document is the second document" d?: "this is the third one" k ? d3: "is this the first document" We have a corpus of 4 total documents. The for t = "document", t appears in 3 different documents. The idf score for "document" is then log(4/3) = 0.2877. Similarly, for t = "first", t appears in 2 different documents. The idf score for "first" is then log(4/2) = 0.6931. The idf score for t= "this" is log(4/4)= 0. The resulting idf scores for the above examples can be laid out like SO: document first is do 0.2877 0.6931 0.0 0.0 d? 0.2877 d? 0.0 d3 0.2877 0.0 0.0 0.0 0.0 0.0 1.3863 one second the third this 0.0 0.0 0.0 0.0 1.3863 0.0 0.0 0.0 0.0 0.0 1.3863 0.0 0.0 0.0 0.0 0.0 26°C ? 0.6931 0.0 0.0
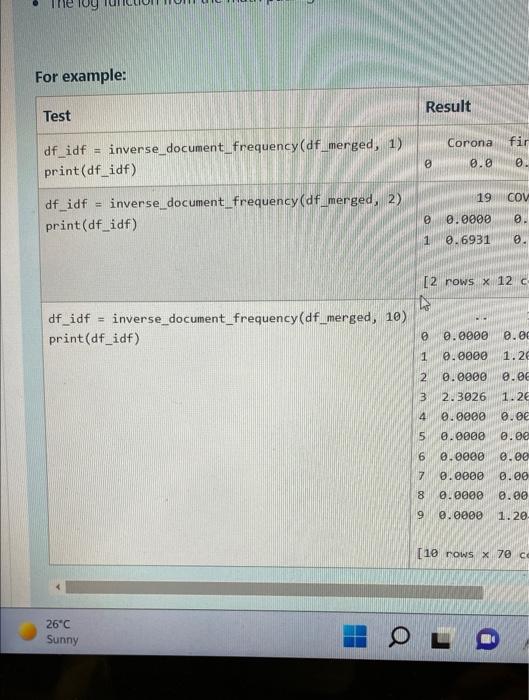
We can get the max values in each column to more easily compare the IDF scores per term. We can see how terms that appear across many documents are weighted less using IDF. document first is one second the third this idfmax 0.2877 0.6931 0.0 1.3863 1.3863 0.0 1.3863 0.0 Write a function inverse_document_frequency(df_merged, top_n) that takes in df merged as the merged dataframe from Task 7 and top_n as the first n rows in this dataframe and outputs a dataframe of the idf scores for every word in the corpus (like in the first table in this description). The resulting scores should be rounded to 4 d.p. The columns must be in sorted alphabetical order. Tips: This task can be performed using a similar methodology to the previous task. • We've given you the tokenize_words (df_merged, top_n) function for you to use, which returns a sorted list of all the unique words found in the corpus. Don't worry about stop-words, punctuation, capitals, etc. like you did in the previous assignment. • We've also given you the document_frequency (df_merged, top_n) function which returns a dictionary where = each unique token found in the corpus and = the number of unique documents the token occurs in across the corpus. The log function from the math package can be used and has been imported for you. For example: Test Result
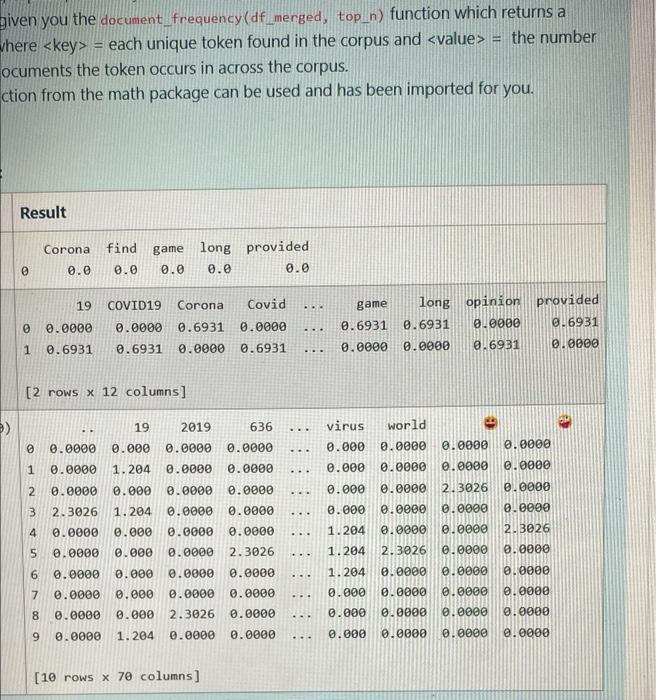
For example: Test Corona fir = inverse document_frequency (df_merged, 1) df_idf print(df_idf) 0 0.0 0. 19 COV df_idf = inverse_document_frequency (df_merged, 2) 0 print (df_idf) 0.0000 0 1 0.6931 0. [2 rows x 12 c 4 inverse document_frequency (df_merged, 10) df_idf = print (df_idf) 0 0.0000 0.00 1 0.0000 1.26 2 0.0000 0.06 3 2.3026 1.26 4 0.0000 0.00 5 0.0000 0.00 0.0000 0.00 7 0.0000 0.00 0.0000 0.00 9 0.0000 1.20- [10 rows x 70 ce 26°C Sunny O 678 a Result
given you the document_frequency (df_merged, top_n) function which returns a = where each unique token found in the corpus and = the number ocuments the token occurs in across the corpus. ction from the math package can be used and has been imported for you. Result Corona find game long provided 0 0.0 0.0 0.0 0.0 0.0 19 COVID19 Corona Covid 0.0000 0.0000 0.6931 0.0000 1 0.6931 0.6931 0.0000 0.6931 [2 rows x 12 columns] 19 2019 636 0.0000 0 0.0000 0.000 0.0000 1 0.0000 1.204 0.0000 0.0000 2 0.0000 0.000 0.0000 0.0000 3 2.3026 1.204 0.0000 0.0000 4 0.0000 0.000 0.0000 0.0000 5 0.0000 2.3026 0.0000 0.000 6 0.0000 0.000 0.0000 0.0000 7 0.000 0.0000 0.0000 0.0000 0.0000 0.000 2.3026 0.0000 8 9 0.0000 1.204 0.0000 0.0000 [10 rows x 70 columns] (E 0 00 .. ... .... ... ... ... ... ……. ... ... .... .... game long opinion provided 0.0000 0.6931 0.6931 0.6931 0.0000 0.0000 0.6931 virus world 0.000 0.0000 0.0000 0.0000 0.000 0.0000 0.0000 0.0000 0.0000 2.3026 0.0000 0.000 0.000 0.0000 0.0000 0.0000 1.204 0.0000 0.0000 2.3026 1.204 2.3026 0.0000 0.0000 1.204 0.0000 0.0000 0.000 0.0000 0.0000 0.0000 0.000 0.0000 0.0000 0.0000 0.000 0.0000 0.0000 0.0000 ... ... ... 0000¹0 000010
Expert Answer
def inverse_document_frequency(df_merged,top_n): doc_freq = document_frequency(df_merged,top